How we ran a Multi-Layer Perceptron and ResNet-20 with the Microsoft Cognitive Toolkit on RISC-V
At Emdalo Technologies, we specialize in Artificial Intelligence solutions at the Edge.
Over the past year or two, we decided to explore RISC-V, the free and open Instruction Set Architecture (ISA) that’s taking the semiconductor industry by storm. In particular, we were curious about how we would use this architecture with some of our Edge AI solutions.
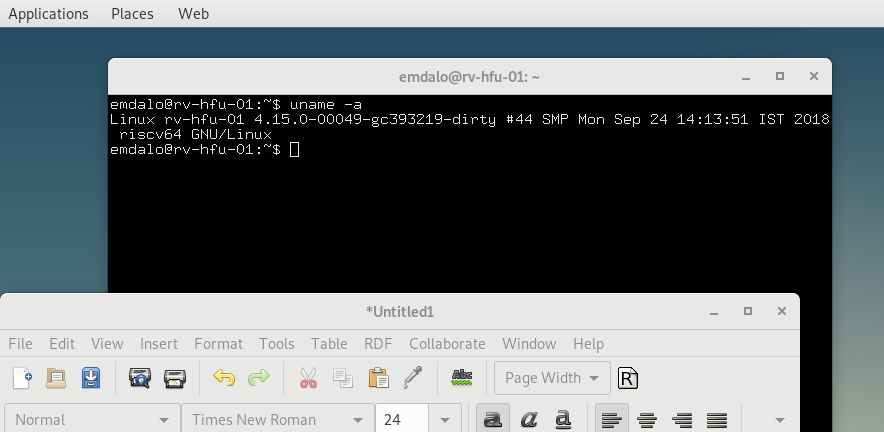
The platform of SiFive's HiFive Unleashed board in conjunction with Microsemi's HiFive Unleased Expansion board provides an interest desktop-like environment on which to develop applications for RISC-V. Western Digital have released a tutorial describing how to get Fedora’s Gnome Desktop running on RISC-V. We've had success in getting a Debian environment running using similar hardware.
Another favorite technology of ours is “The Microsoft Cognitive Toolkit”, previously known as the CNTK. The Cognitive toolkit has a number of desirable attributes when compared to incumbant frameworks, such as supporting both CPU and GPU variants, cross platform (Linux, Windows, x86, ARM64), bindings for multiple languages, strong support for the Open Neural Network Exchange (ONNX) format, and blazingly fast parallelizable training. Additionally, being later to the game, it has benefitted from stepping over mistakes previous toolkits have made, resulting in a clean and easy to use API. The Cognitive Toolkit has improved release after release, and it now has a thriving community with lots of examples for various types of network.
We thought why not port the Cognitive Toolkit to Linux on our RISC-V development platform? Initially this began as an experiment, but as it is our favorite and most productive toolkit porting it enables us to develop applications and demos for our customers and demonstrate them on the RISC-V architecture.
The porting involved several crude changes initially, but we have achieved excellent results already and are in the process of tidying this up further. With these changes, we managed to get the Cognitive Toolkit and its Python bindings (versions 2.7 and 3.6) to build and run successfully on RISC-V. For example, here is the toolkit training a multi-layer perceptron network from scratch for MNIST:
$ python SimpleMNIST.py ------------------------------------------------------------------- Build info: Built time: Oct 11 2018 18:39:02 Last modified date: Mon Sep 24 17:47:55 2018 Build type: release Build target: CPU-only With ASGD: no Math lib: openblas Build Branch: master Build SHA1: ce503f8dd769c2adfd558a5b522c89ef4b5bca57 (modified) MPI distribution: Open MPI MPI version: 1.10.3 ------------------------------------------------------------------- Learning rate per 1 samples: 1.0 Finished Epoch[1 of 10]: [Training] loss = 0.380820 * 60032, metric = 10.33% * 60032 81.586s (735.8 samples/s); Finished Epoch[2 of 10]: [Training] loss = 0.199452 * 59968, metric = 5.58% * 59968 69.294s (865.4 samples/s); Finished Epoch[3 of 10]: [Training] loss = 0.155059 * 60032, metric = 4.41% * 60032 69.226s (867.2 samples/s); Finished Epoch[4 of 10]: [Training] loss = 0.128004 * 59968, metric = 3.59% * 59968 69.283s (865.6 samples/s); Finished Epoch[5 of 10]: [Training] loss = 0.110124 * 60032, metric = 3.12% * 60032 69.540s (863.3 samples/s); Finished Epoch[6 of 10]: [Training] loss = 0.096090 * 59968, metric = 2.65% * 59968 69.238s (866.1 samples/s); Finished Epoch[7 of 10]: [Training] loss = 0.085009 * 60032, metric = 2.40% * 60032 69.519s (863.5 samples/s); Finished Epoch[8 of 10]: [Training] loss = 0.076447 * 59968, metric = 2.17% * 59968 69.380s (864.3 samples/s); Finished Epoch[10 of 10]: [Training] loss = 0.063176 * 59968, metric = 1.76% * 59968 69.096s (867.9 samples/s); ElementTimes6 forward avg 0.029727s, backward avg 0.000000s (fwd# 9|bwd# 0) Hardmax204 forward avg 0.000256s, backward avg 0.000000s (fwd# 9|bwd# 0) Minus189 forward avg 0.000000s, backward avg 0.000000s (fwd# 0|bwd# 0) Minus210 forward avg 0.000050s, backward avg 0.000000s (fwd# 9|bwd# 0) Plus137 forward avg 0.043914s, backward avg 0.000000s (fwd# 9|bwd# 0) Plus155 forward avg 0.041462s, backward avg 0.000000s (fwd# 9|bwd# 0) ReduceElements183 forward avg 0.000000s, backward avg 0.000000s (fwd# 0|bwd# 0) ReduceElements222 forward avg 0.000045s, backward avg 0.000000s (fwd# 9|bwd# 0) ReduceElements225 forward avg 0.000000s, backward avg 0.000000s (fwd# 0|bwd# 0) ReLU139 forward avg 0.002152s, backward avg 0.000000s (fwd# 9|bwd# 0) Times135 forward avg 0.324488s, backward avg 0.000000s (fwd# 9|bwd# 0) Times153 forward avg 0.004735s, backward avg 0.000000s (fwd# 9|bwd# 0) TransposeTimes186 forward avg 0.000000s, backward avg 0.000000s (fwd# 0|bwd# 0) TransposeTimes207 forward avg 0.000379s, backward avg 0.000000s (fwd# 9|bwd# 0) Error: 0.025282
And here it is executing a pre-trained ResNet-20 model against CIFAR-10:
$ python3 ResNet_20_CIFAR10_CNTK.py Using Microsoft Cognitive Toolkit version 2.6+ Using numpy version 1.14.5 The Cognitive Toolkit is using the CPU for processing. Selected CPU as the process wide default device. make_model is false, so skipping training... Reusing locally cached: ./data/CIFAR-10/ResNet_20_CIFAR10_CNTK.model Composite(Tensor[3,32,32]) -> Tensor[10] Evaluating model output node 'prediction' for 100 images. Processed 100 samples (84.00% correct) 84 of 100 prediction were correct
We have found the combination of the SiFive multicore RISC-V with the Microsemi FPGA provides a wonderful platform for prototyping all manner of AI experiments. The RISC-V ecosystem is alive and vibrant, and a definite hotbed for future (non-GPGPU based) AI and Deep Learning platforms.
Currently, we are continuing our work in tidying up our modifications, and in accelerating the framework to run faster on RISC-V through tighter code and FPGA acceleration. We are also exploring opportunities where we can help migrate some of our customers’ platforms to a combination of RISC-V plus FPGA.
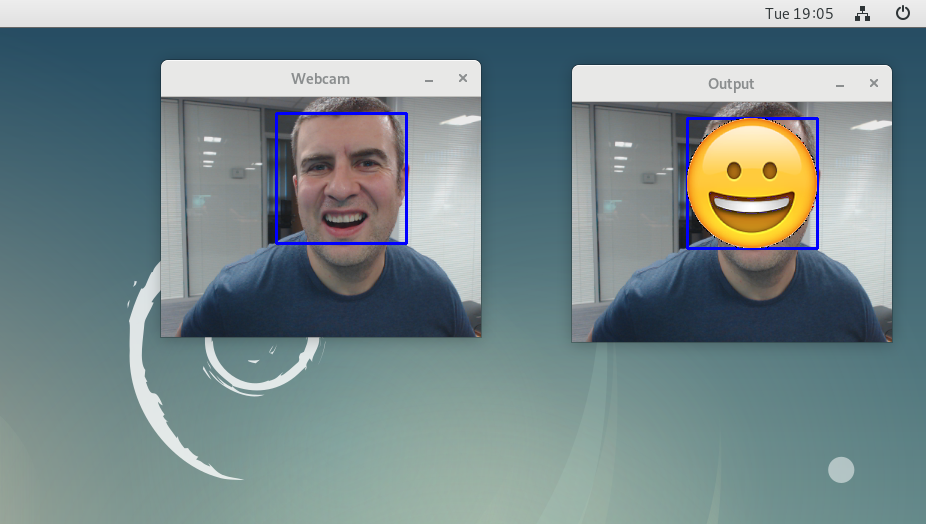
We even had a little fun getting OpenCV up and going on the platform, and then running CNNs on live input from our webcam. It takes a couple of seconds per classification, but we’re happy with this as we are still actively optimizing performance. Here is an example of an emotion recognition network running on our RISC-V system:
We have links to cntk-2.6-cp27-cp27mu-linux_riscv64.whl and cntk-2.6-cp36-cp36mu-linux_riscv64.whl for installation on a RISC-V system via pip, and to a diff of our modified source tree to allow reproducibility of this build.
Links:
Diff to modified CNTK 2.6 source (apply to https://github.com/Microsoft/CNTK.git hash ce503f8dd769c2adfd558a5b522c89ef4b5bca57)
RISCV-config.guess (needed for SWIG)
Debian SDA image for HiFive Unleashed (includes Gnome 3 desktop, Quake with sound, Caffe, CNTK, and OpenCV)

